

Cosa si intende per Data Mining?
Il Data Mining consiste nell’elaborazione di ingenti quantità di dati attraverso meccanismi computazionali, al fine di estrarne informazioni significative sotto forma di regole e configurazioni (pattern).
In altri termini, si tratta di un processo complesso di identificazione di tendenze nei dati, con lo scopo di cercare modelli o trend potenzialmente utili e comprensibili e tali da consentire all’utente di prendere decisioni cruciali in modo ragionevole.
Dunque, tutte le analisi che vengono effettuate con questi programmi sono innanzitutto frutto degli input che i ricercatori decidono di inserire e di non inserire, di impostare in un certo modo piuttosto che in un altro…
Prima di addentrarci nell’ambito che ci riguarda, quello finanziario, ci teniamo ad aprire una parentesi sulle altre discipline, come tentativo di riflessione sulla portata e le potenzialità che contraddistinguono il Data Mining.
Vuoi rimanere aggiornato sugli articoli del blog e sui nostri approfondimenti?
Quali settori si affidano a questo strumento per affinare le loro ricerche e migliorare i loro business?
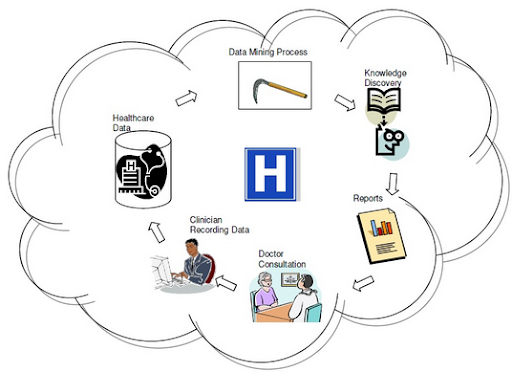
Il settore sanitario
lo impiega diffusamente sia per la valutazione dell’efficacia di nuovi trattamenti terapeutici, sia a livello assicurativo per prevenire frodi e abusi. Infatti il campo medico oggi genera un enorme ammontare di dati complessi relativi a pazienti, alle risorse ospedaliere, alla diagnosi di malattie, alle cartelle cliniche, ai dispositivi medici, ecc. Tutti questi dati, una volta processati e analizzati, costituiscono una risorsa chiave per l’estrapolazione di conoscenza, essenziale per potenziare l’ efficienza a livello di costi (in tal modo i pazienti possono ricevere cure migliori ad un prezzo inferiore) e per indirizzare le decisioni dei medici.
Le tecniche di Data Mining
vengono diffusamente applicate ai dati presenti sul web, da colossi come Google, Facebook, Amazon, ecc.
Google si affida al Data Mining sia per le ricerche, sia per la pubblicità. Infatti, l’uso di algoritmi di apprendimento più semplici e standard, è diventato non più sufficiente a far fronte ai continui cambiamenti che interessano i dati e al loro crescente e inesauribile volume.
Ogni singola azione eseguita sul web viene memorizzata all’interno di un’immensa base di dati e lì viene incrociata con altre informazioni contenute su altre basi di dati, attraverso raffinati algoritmi di tipo matematico statistico.
Facebook calcola quali post visualizza un utente, quanto è vicino questo utente al creatore del post, quanto è importante il contenuto (soprattutto attraverso le foto considerate più significative e attraverso il testo) e per quanto tempo è stato utilizzato quel post. Pesando questi vari fattori, l’algoritmo decide cosa mostrare, aggiornandosi e migliorandosi periodicamente.
Amazon, invece, suggerisce quali libri potrebbero piacere agli utenti, sulla base degli acquisti effettuati da utenti considerati con caratteristiche affini.

Non c’è dubbio che il futuro del web appartenga a chi dispone delle più sofisticate tecniche di estrazione dei dati.
L’industria immobiliare
I sistemi di analisi di Big Data consentono di effettuare previsioni di risultati e comportamenti fondamentali per determinare il successo, ad esempio, di piani di valorizzazione e riposizionamento di immobili.
L’utilizzo su larga scala di basi informative georeferenziate offre inoltre un prezioso supporto alla valutazione della capacità di attrazione del territorio e alla definizione del pricing delle case. Supponiamo di conoscere le caratteristiche e i prezzi di un campione di case: tramite la costruzione di un modello computazionale, è possibile calcolare rapidamente il prezzo a cui è congruo vendere un’abitazione.
In maniera altrettanto speculare si potrebbe costruire un sistema da utilizzare per la scelta dei titoli societari da tenere in portafoglio basandosi sul price earning e su altri dati fondamentali societari, oppure su valori legati all’analisi macro-fondamentale.
Appurato che è l’uomo ad influenzare e determinare le scelte in base alle proprie conoscenze e alle sue idee, la macchina non solo è un valido supporto per la loro implementazione, ma è fondamentale per incrementarne il grado di solidità. In altri termini, la convinzione che i mezzi computerizzati siano meno affidabili delle decisioni umane, per noi è totalmente ribaltata. La vera black box è l’approccio discrezionale. L’effettiva trasparenza la può trasmettere solo un approccio strutturato attraverso un rigoroso Metodo Scientifico.
nota: Il metodo scientifico è la modalità con cui la scienza procede per raggiungere una conoscenza della realtà oggettiva, affidabile, verificabile e condivisibile. Tale approccio si sviluppò nel sedicesimo secolo e uno dei primi studiosi a metterlo in pratica fu Galileo.
Che cos’è una Black-Box? Approfondiscilo in questo articolo:
“Il connubio tra mente umana e data mining sui dati finanziari”
Sinteticamente:
- I dati storici sono elaborati attraverso strumenti matematico-statistico
- le previsioni devono essere falsificabili e verificabili
- i risultati devono essere ripetibili
Infatti, solo attraverso un atteggiamento critico sostenuto da un’opportuna strumentazione possiamo renderci conto di quanto un sistema, che all’apparenza sembra portare a dei risultati ineccepibili, si possa facilmente e rapidamente rompere.
La macchina, quindi, rende tangibilmente consapevoli della fragilità di certe convinzioni. Una volta definite le regole che la strategia deve rispettare in modo chiaro e sequenziale e implementato l’algoritmo, un sistema viene sottoposto alle migliaia di prove differenti che i programmi in questione consentono di eseguire.
Paradossalmente, a catalizzare tempo e risorse, non è tanto la mera ricerca di strategie, quanto la fase di stress test, proprio per la consapevolezza dei limiti e dei pericoli in cui si può incorrere.
Per chiudere il cerchio che avevamo aperto all’inizio a proposito delle White Box, la chiave della robustezza del procedimento e, soprattutto, dei risultati che siamo in grado di ottenere sono il Backtesting e, in senso lato, l’approccio falsificazionista, al di là delle varie e vane resistenze umane.
Per un approfondimento sul Data Mining, leggi anche il nostro articolo “Data Mining: meglio l’uomo o la macchina? Le riflessioni di 4Timing SIM”.

CIO & Founder 4Timing SIM – Lavoro nel mondo della gestione del risparmio da quasi trent’anni con lo stesso entusiasmo di quando ho iniziato. In questi ultimi venti anni, coadiuvato dal mio staff, mi sono dedicato all’implementazione di modelli sistematici di gestione attraverso l’applicazione del metodo scientifico, sempre pronto a valutare nuove possibilità ma con l’occhio critico della scienza. Mi rispecchio nella frase del filosofo Karl Popper: “Il metodo della scienza è il metodo di audaci congetture e ingegnosi e severi tentativi di confutarle.” Nel 2016 ho deciso di fondare 4Timing SIM per offrire, attraverso i servizi di consulenza finanziaria e gestione del patrimonio, il know-how accumulato in questi anni.





